
The New EDW: Meet the Big Data Stack Technology
Enterprise Data Warehouse Definition: Then and Now
What is an EDW?
Historically, the Enterprise Data Warehouse (EDW) was a core component of enterprise IT architecture. It was the central data store that holds historical data for sales, finance, ERP and other business functions, and enables reporting, dashboards and BI analysis.
Today, the definition of the EDW is expanding. It is becoming a “stack”, not a monolithic system you build and maintain.
EDW as Monolithic Enterprise System
To many organizations, the EDW is a corporate system made up of several components:
- Central Enterprise Data Warehouse from vendors like Oracle, SAP and Teradata.
- Data marts deployed in specific departments containing a subset of organizational data. While data warehouse theory suggested either central EDW or individual data marts, in reality many organizations combine models and have both.
- Online Analytical Processing (OLAP) server that processes complex queries on the data.
- Extract Transform Load (ETL) software from vendors like Informatica, which automates complex data pipelines.
- BI and reporting tools received structured data from the data warehouse and used it to produce reports and visualizations of business metrics.

This is the old definition of EDW - it views the Enterprise Data Warehouse as a rigid, monolithic system that is build once and maintained. It “does what it does” and cannot evolve to support other needs or new types of data. By definition it is a big, heavy and expensive piece of infrastructure.
EDW as a Stack: Out with Complexity, No Need for Details
Think of a personal computer. There is a technology stack that powers our experience, from motherboard, CPU and disk storage, through to BIOS, operating system, and specific applications.
The higher up a component is in the stack, the more we as users care about it. We don’t care what version of BIOS we are using, and it’s less important to us if it’s Windows 7 or Windows 10. We start caring at the application layer, for example if it’s Microsoft Word or Google Docs. We don’t need to understand or even know about the lower layers of the stack. They are transparent and taken care of for us.
Today, organizations just “don’t care” about the inner working of an EDW. They want a solution that manages data and derives insights. Things like ETL, OLAP and storage engines are like the BIOS to them - it should simply work and they don’t want to worry about it.
Hadoop and data lake technology, which were at one point considered an alternative to the traditional Enterprise Data Warehouse, are now understood to be only part of the big data stack. You can’t replace an EDW with Hadoop, but you can replace the monolithic storage and data processing elements of an EDW with one of several next-generation technologies, such as Hadoop, ElasticSearch, Amazon S3, and so on.
Here is our view of the big data stack.
- The top layer - analytics - is the most important one. Analysts and data scientists use it. It’s not part of the Enterprise Data Warehouse, but the whole purpose of the EDW is to feed this layer.
- The lower layers - processing, integration and data - is what we used to call the EDW. These are technology layers that need to store, bring together and process the data needed for analytics. Old EDW technology can still function in these lower layers. Or it can be replaced by cloud-based technology that is easier to set up and manage.
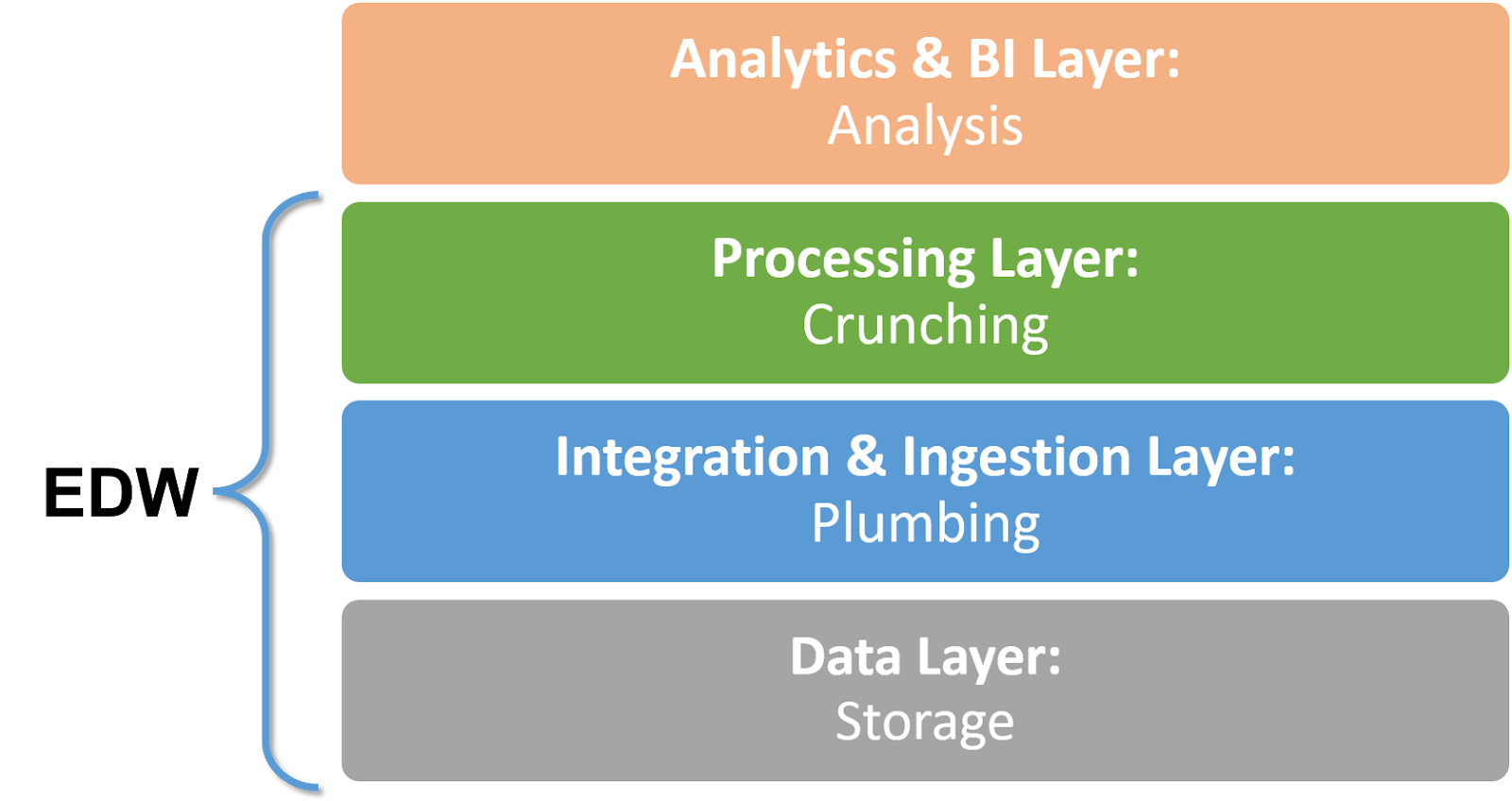
The New EDW: Layers and Technology Options
According to our view of the EDW as part of the big data stack, here are the technologies that organizations can pick and choose to build their stack.
Data Layer
Today many organizations manage petabyte-scale data. The requirements are to store massive amounts of raw data, and not just Online Transaction Processing (OLTP) style data like in the old EDW - semi structured and unstructured data is growing in importance.
The data layer can be:
- On-premise - raw data stored in relational databases like PostgreSQL or MySQL, NoSQL databases like Cassandra or MongoDB, which can also handle unstructured data, or for very large data, Hadoop HDFS.
- In the cloud - data stored using services like Amazon S3, Amazon Elastic File Storage (EFS), Amazon Elastic Block Storage (EBS), and Azure Blob Storage.
Integration and Ingestion Layer
This layer adds new data into the data layer, and combines data in ways that are meaningful for analysis. Instead of a heavy ETL process that is meticulously designed and tested, for specific data and information flows, this is a flexible system that can add data to the flow and juggle it around to suit current business requirements.
The integration layer can be based on:
- Traditional ETL systems - like Informatica, Talend, etc.
- Cloud-based ETL services - like Stitch and Blendo. These tools can pull in data sources, both cloud-based and on-prem, in a matter of seconds, set up transformations and pipe the data back to the data layer for storage, to data warehouses for processing and ongoing reporting, or directly to BI tools.
Processing Layer
This is where the data warehouse itself lives, tasked with taking all the data, structuring it into a format suitable for OLAP and SQL queries, optimizing it, and handing it over to analysis tools.
The processing layer can be based on:
- Old style EDW products like SAP BW and Teradata EDW.
- Cloud-based data warehouses like Amazon Redshift, Google BigQuery and Panoply. These are offered on a pay-per-use basis, requiring no upfront investment, and provide vastly improved performance and unlimited scalability compared to on-premise data warehouses.
It’s not either-or. Just like in a data mart strategy, an organization can maintain several data warehouses. For example, use an on-premise system for sensitive data with compliance requirements, and leverage cloud-based systems for other data.
Analytics & BI Later
Although analytics and BI are not strictly part of the EDW, in this extended view of the data stack, they should be. We suggest that the broader EDW stack should also contain big data analysis and visualization tools:
- Data extraction and parsing tools - can make sense of large volumes of unstructured data, such as scraped website data. Examples are OpenRefine and Import.io.
- Sentiment and language analysis tools - can extract meaning from textual content, using techniques like sentiment analysis, entity extraction and clustering. Examples are Opentext Content Analytics and IBM Watson.
- Data mining tools - used to discover hidden insights in huge volumes of data. Examples are Orange and Kaggle.
- Data visualization and BI tools - the “icing on the cake”, allowing analysts and data scientists to explore data and build dashboards and charts answering business questions. Examples are Tableau, Chartio and Looker.
Automation in the New EDW Stack
In the new EDW stack, things move fast. Data flows instantly from sources to data storage, is immediately processed by cloud-based data warehouses, and pushed to data analysis and BI solutions. New data sources appear all the time and data volumes continue to grow.
In this environment, there is no time for a team of data engineers to sit down and meticulously plan, test, stage and deploy data transformations, as they would do for months in a traditional EDW project. Organizations need the data now, and they need it to be cleaned, high quality and in a structure that facilitates analysis.
The solution is data warehouse automation. The new EDW, composed of all the types of tools we listed above, should be able to automate all stages of the data pipelines:
- Instant data ingestion - the EDW should ingest data at the click of a button, with no need for large file uploads, format conversions, encoding, schema analysis, etc.
- Automated data cleaning and preparation - the EDW should automatically recognize patterns in the data, remove irrelevant or erroneous data and prepare data for analysis.
- Easy, ad-hoc data transformations - analysts should be able to define their interests and easily transform data, even very large data sets, into a format that facilitates analysis. This should happen in 5 minutes and should not be reliant on data engineers.
Panoply is a cloud data platform that combines ETL and data warehousing with a hassle-free interface. Panoply allows analysts to pull together huge data sets and start deriving insights in minutes, with no reliance on data engineers. It plays well with other elements in the new EDW stack, including a variety of data sources, cloud-based ETL services and modern BI tools.
The Future of EDW
In the future, we will say “enterprise data warehouse” but mean much more. The original vision of the EDW was to be a core organizational infrastructure managing data for business analysis and visibility. Today, an entire stack of big data tools serves this exact purpose - but in ways the original data warehouse architects never imagined.
In 2020, 2030 and beyond - say goodbye to the EDW as an organizational system someone bought and installed. And start thinking of EDW as an ecosystem of tools that help you go from data to insights.
Get a free trial of Panoply to see how modern data warehouse technology can support this vision by fully automating the data pipeline in the cloud.