
Redshift ETL: How to Load Data into AWS Redshift Warehouse
It’s easier than ever to load data into the Amazon Redshift data warehouse. There are three primary ways to extract data from a source and load it into a Redshift data warehouse:
- Build your own ETL workflow
- Use Amazon’s managed ETL service, Glue
- Use one of several third-party cloud ETL services that work with Redshift
In this post you’ll learn how AWS Redshift ETL works and the best method to use for your use case.
What is ETL?
Extract-Transform-Load (ETL) is the process of pulling structured data from data sources like OLTP databases or flat files, cleaning and organizing the data to facilitate analysis, and loading it to a data warehouse.
What is Amazon Redshift?
Redshift is a petabyte-scale, managed data warehouse from Amazon Web Services. You can easily build a cluster of machines to store data and run very fast relational queries. Start small and scale up indefinitely by adding more machines or more Redshift clusters (for higher concurrency).
1. Build your own Redshift ETL Pipeline
Amazon recommends you design your ETL process around Redshift’s unique architecture, to leverage its performance and scalability.
Follow these best practices to design an efficient ETL pipeline for Amazon Redshift:
-
COPY from multiple files of the same size—Redshift uses a Massively Parallel Processing (MPP) architecture (like Hadoop). Workloads are broken up and distributed to multiple “slices” within compute nodes, which run tasks in parallel. Ensure each slice gets the same amount of work by splitting data into equal-sized files, between 1MB-1GB.
-
Bulk load data from S3—retrieve data from data sources and stage it in S3 before loading to Redshift. Use Amazon manifest files to list the files to load to Redshift from S3, avoiding duplication. Use temporary staging tables to hold data for transformation, and run the
ALTER TABLE APPENDcommand to swap data from staging tables to target tables. This is faster thanCREATE TABLE ASorINSERT INTO. -
Multiple steps in a single transaction—commits to Amazon Redshift are expensive. If you have multiple transformations, don’t commit to Redshift after every one. Run multiple SQL queries to transform the data, and only when in its final form, commit it to Redshift. Below is an example provided by Amazon:
Begin
CREATE temporary staging_table;
INSERT INTO staging_table SELECT .. FROM source (transformation logic);
DELETE FROM daily_table WHERE dataset_date =?;
INSERT INTO daily_table SELECT .. FROM staging_table (daily aggregate);
DELETE FROM weekly_table WHERE weekending_date=?;
INSERT INTO weekly_table SELECT .. FROM staging_table(weekly aggregate);
Commit
-
Perform table maintenance regularly—Redshift is a columnar database. To avoid performance problems over time, run the
VACUUMoperation to re-sort tables and remove deleted blocks. Frequently run theANALYZEoperation to update statistics metadata, which helps the Redshift Query Optimizer generate accurate query plans. The Analyze & Vacuum Utility helps you schedule this automatically. -
Use workload management—Redshift is optimized primarily for read queries. To avoid commit-heavy processes like ETL running slowly, use Redshift’s Workload Management engine (WLM). Define a separate workload queue for ETL runtime. Configure to run with 5 or fewer slots, claim extra memory available in a queue, and take advantage of dynamic memory parameters.
-
Use
UNLOADto extract large result sets—in Redshift, fetching a large number of rows usingSELECTstalls the cluster leader node, and thus the entire cluster. Instead, use theUNLOADcommand to extract large result sets directly to S3, writing data in parallel to multiple files, without stalling the leader node. -
Use Amazon Redshift Spectrum for ad hoc processing—for ad hoc analysis on data outside your regular ETL process (for example, data from a one-time marketing promotion) you can query data directly from S3. Amazon Redshift Spectrum can run ad-hoc relational queries on big data in the S3 data lake, without ETL.
-
Monitor daily ETL health using diagnostic queries—use monitoring scripts provided by Amazon to monitor ETL performance, and resolve problems early before they impact data loading capacity.
For more details on these best practices, see this excellent post on the AWS Big Data blog.
2. Redshift with AWS Glue
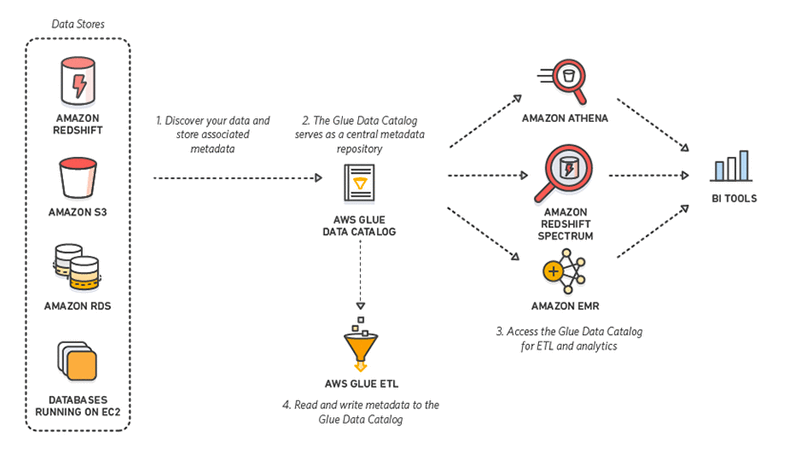
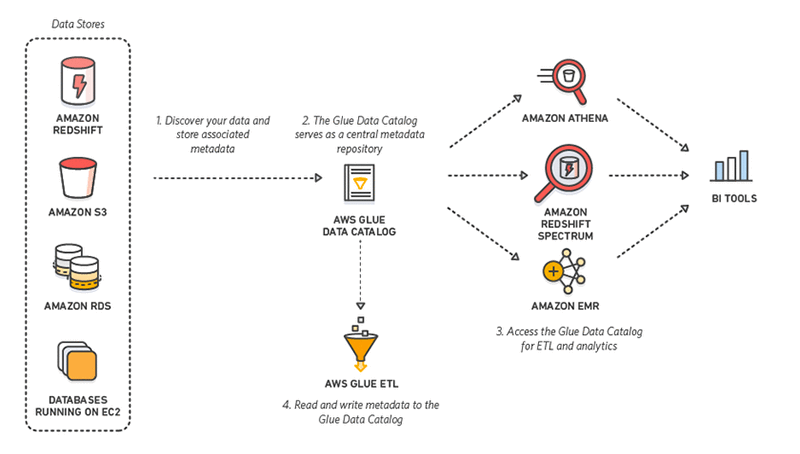
Amazon Web Services offers a managed ETL service called Glue, based on a serverless architecture, which you can leverage instead of building an ETL pipeline on your own.
The advantage of AWS Glue vs. setting up your own AWS data pipeline, is that Glue automatically discovers data model and schema, and even auto-generates ETL scripts. However, it comes at a price—Amazon charges $0.44 per Digital Processing Unit hour (between 2-10 DPUs are used to run an ETL job), and charges separately for its data catalog and data crawler.
{kind=link}
AWS Glue offers the following capabilities:
-
Integrated Data Catalog—a persistent metadata store that stores table definitions, job definitions, and other control information to help you manage the ETL process. Glue automatically creates partitions to make queries more efficient.
-
Automatic schema discovery—Glue crawlers connect to your data, runs through a list of classifiers to determine the best schema for your data, and creates the appropriate metadata in the Data Catalog.
-
Code generation—Glue automatically generates Scala or Python code, written for Apache Spark, to extract, transform, flatten, enrich, and load your data.
-
Developer endpoints—Glue connects to your IDE and let you edit the auto-generated ETL scripts. Add custom readers, writers, or transformations as custom libraries.
-
Job scheduler—Glue runs ETL jobs in parallel, either on a pre-scheduled basis, on-demand, or triggered by an event. It lets you define dependencies to build complex ETL processes. Logs are pushed to CloudWatch.
3. Third-Party Redshift ETL Tools
You can leverage several lightweight, cloud ETL tools that are pre-integrated with Amazon Redshift. The main advantages of these services is that they come pre-integrated with dozens of external data sources, whereas Glue is only integrated with Amazon infrastructure.
If all your data is on Amazon, Glue will probably be the best choice. Run a simulation first to compare costs, as they will vary depending on use case.
Stitch to Redshift
Stitch lets you select from multiple data sources, connect to Redshift, and load data to it. Stitch provides detailed documentation on how data loading behaves depending on the status of keys, columns and tables in Redshift. Stitch does not allow arbitrary transformations on the data, and advises using tools like Google Cloud Dataflow to transform data once it is already in Redshift.
Blendo to Redshift
Blendo lets you pull data from S3, Amazon EMR, remote hosts, DynamoDB, MySQL, PostgreSQL or dozens of cloud apps, and load it to Redshift. Blendo offers automatic schema recognition and transforms data automatically into a suitable tabular format for Amazon Redshift.
Get More with Panoply
Panoply is a leading cloud data platform. We combine ETL and data warehousing with a hassle-free user interface. Setup takes just a few minutes, so you can start syncing and storing your data almost immediately. And once it’s stored, you can connect your existing BI and analytical tools so you can find insights more quickly.
Learn More About Amazon Redshift, ETL and Data Warehouses