
Redshift Cluster 101
Amazon Redshift is a popular cloud service from Amazon Web Services, which provides a fully-managed analytical data warehouse. One of Redshift’s key features is its dynamic clustering mechanism, which enables it to handle Petabyte-scale data at blazing speeds.
In this page you will learn about:
- Redshift Cluster Basics - concepts and architecture
- Cluster Management Options - four ways to manage a cluster in Redshift
- Creating a Cluster - a brief guide to setting up a cluster via the AWS console
- Common Cluster Operations - how to modify, delete, resize and reboot a cluster
- Creating a Cluster in a VPC - creating a cluster on Amazon’s Virtual Private Network
- Redshift Clustering Challenges - difficulties you might encounter with Redshift clustering
Cluster Basics
A cluster is the core unit of operations in the Amazon Redshift data warehouse. Each Redshift cluster is composed of two main components:
- Compute Node, which has its own dedicated CPU, memory, and disk storage. Compute nodes store data and execute queries and you can have many nodes in one cluster.
- Leader Node, which manages communication between the compute nodes and the client applications. The leader node compiles code, distributes the compiled code to the compute nodes, and assigns a portion of the data to each compute node.
Redshift’s cluster and node organization represents a Massively Parallel Processing (MPP) architecture. MPP is a technology that allows multiple processors to perform many operations at a time.
Some key advantages of MPP architecture for databases are:
- Ability to query large volumes of data at speed.
- Good for analytic workloads, which require sophisticated queries.
- Linearly scalable to cater for data growth.
- Flexible enough to incorporate unstructured and semi-structured data.
Cluster Management Options
There are four main options for managing clusters in Redshift.
-
Console: The console is the main dashboard on Redshift that lets you manage your data. In the console, you can create, modify, and delete clusters by clicking a few buttons.
- Java AWS SDK: You can perform cluster management operations using the Java programming language with Amazon’s own software development kit. You can interact with Redshift using an SDK for any one of several platforms, including Java, .NET, PHP, Python, and Ruby.
- Redshift CLI: The Redshift command line interface lets you manage your clusters with command line operations using the Python programming language. You can run cluster operations from your preferred terminal program.
- Redshift API: You can also use the Redshift QUERY API to manage clusters. To use this method, you call the API by submitting a HTTP or HTTPS request.
The remainder of this article gives you a quick overview on how to create a cluster in the Redshift Console and perform common cluster operations.
Creating A Cluster
Parameters
In Redshift, you choose a parameter group for each cluster that you create. The parameter group contains the settings used to configure the database. If you fail to choose a parameter group, Redshift allocates its own default parameter group to your cluster.
In the console, you can create or modify parameter groups on the Parameter Groups page as shown below.
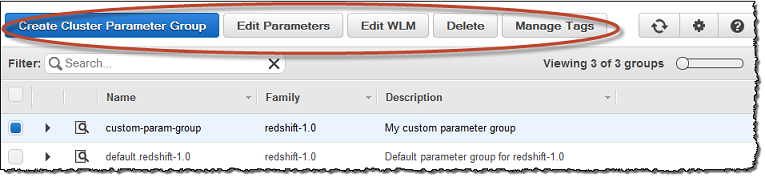 Source: Amazon Web Services
Source: Amazon Web Services
The main cluster parameters are:
- analyze_threshold_percent This parameter sets a threshold for analyzing a table, which is an operation used to update table statistics. When a table has a lower percentage of changed rows since the last ANALYZE operation than the parameter specifies, Redshift skips the ANALYZE command for that table.
- datastyle Use this parameter to specify the format of data (ISO, Postgres, SQL, or German) and year/month/day ordering (DMY, MDY, YMD).
- enable_user_activity_logging Lets you choose whether to enable Redshift to create a log of information about connections and user activities in your database.
- extra_float_digits Sets the number of digits displayed for floating-point values.
- query_group A character string that you use to apply a user-defined label to a group of queries.
- require_SSL Choose whether your cluster should require an SSL connection to allow client connections.
- search_path This parameter is a comma-separated list of existing schema names. The parameter specifies the order in which schemas are searched when a table or other object is referenced with no schema component.
- statement_timeout Any statement taking longer than your specified number of milliseconds gets aborted.
- wlm_json_configuration Lets you define the number of query queues that are available, and how queries are routed to those queues for processing.
Main Steps
The main steps for creating a cluster in the Redshift Console are:
-
Log into Amazon Web Services. Navigate to Redshift and then click the Launch Cluster button.
-
On the Cluster Details page, input the cluster’s basic information:
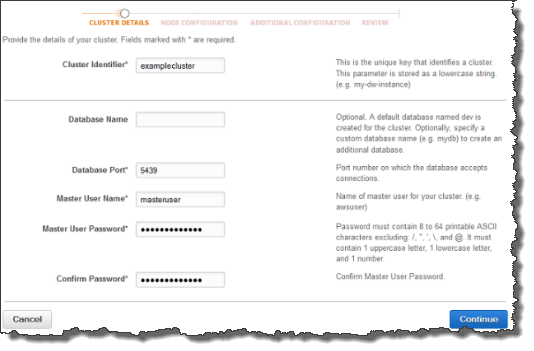
- Cluster identifier: A unique name for your cluster using 1 to 63 alphanumeric characters or hyphens.
- Database name: An optional field for creating a custom database name.
- Database port: A port number between 1150 and 65535 used for connecting to the database from client applications.
- Master user name: An account name for the master of the cluster.
- Master user password: Specify a password for the master account.
- Click the Continue button, and then input information on the Node Configuration page.
Node Type
Choose one of the two node types:
- Dense Compute: These nodes are best for high performance, but they have less storage.
- Dense Storage: Best used for clusters in which you have a lot of data.
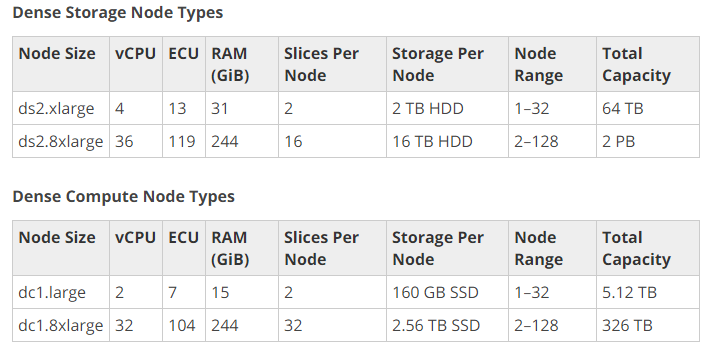 Image source: Amazon Web Services
Image source: Amazon Web Services
Number of Nodes
Select the appropriate number of nodes to store your data. You can choose a single-node cluster, which contains one node that shares leader and compute functionality, or a multi-node cluster, which has a leader node and a user-specified number of compute nodes.The leader node is offered free-of-charge by AWS for a multi-node cluster.
- Click Continue, then fill in relevant information on the Additional Configuration page.
- Cluster parameter group lets you associate a parameter group with the cluster.
- Encrypt database gives you the choice to encrypt all data within the cluster.
- Configure networking options lets you choose whether to launch your cluster in a virtual private cloud (VPC) or outside a VPC.
- Click Continue and go to the Review page. Select Launch Cluster to start creating the cluster.
Further reading:
- Managing clusters using the console
- Managing clusters using AWS SDK for Java
- Managing clusters using the Redshift CLI and API
Common Cluster Operations
The four main cluster operations are:
- Modify: Used to make changes to the cluster.
- Delete: Used to remove a cluster you no longer need.
- Reboot: Restart the cluster so that changes requiring a reboot can take effect.
- Resize: Change the node type, cluster type, or number of nodes.
Modify
To modify a cluster, go through these steps:
- Open the Redshift console and select Clusters. Select the cluster you want to modify.
- On the cluster details page, select Modify from the dropdown menu.
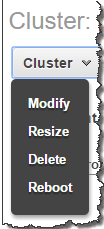
- In the Modify Cluster window, make your desired changes. Common changes include setting a new master password, changing the cluster identifier, and modifying the cluster parameter group.
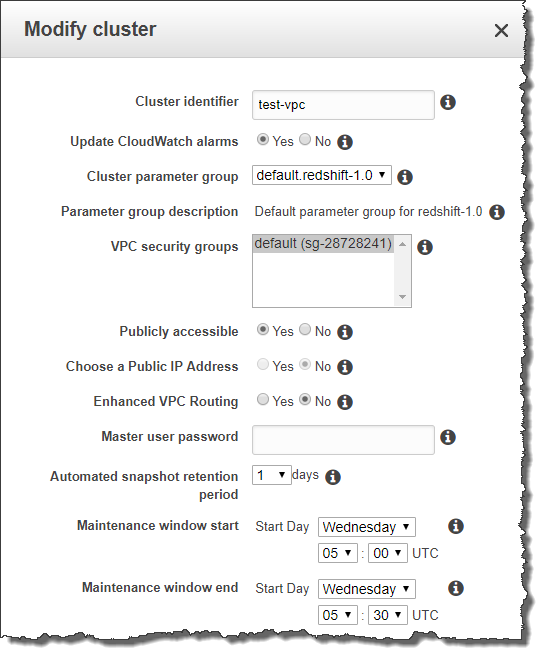
Image source: Amazon Web Services
Further reading: Managing Clusters via the Console
Delete
Follow these steps to delete a cluster:
- Open the Redshift Console, select Clusters, and select the cluster you want to delete.
- On the Configuration tab of your cluster details page, select Cluster, then select Delete from the menu.
- Choose whether to take a final snapshot of the cluster in the Delete Cluster dialog box.
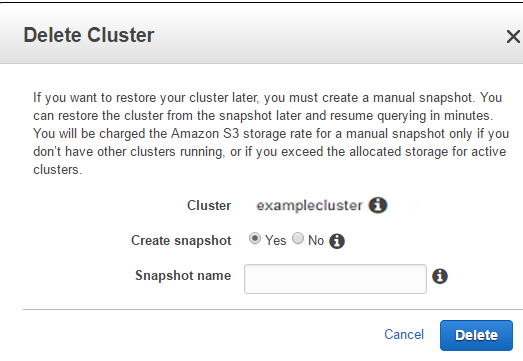
If you delete a cluster without creating a snapshot, all data gets deleted permanently. The delete process typically takes several minutes. Create a snapshot if you plan to use the same data and configuration again.
Further reading: Deleting a Cluster
Reboot
To reboot a cluster:
- Select Clusters in the Redshift console, and select the cluster you want to reboot.
- On the cluster details page, select Cluster and Reboot from the drop-down menu.
- Confirm you want to reboot by clicking the Reboot button in the Reboot Cluster window. Wait several minutes for the reboot to finish.
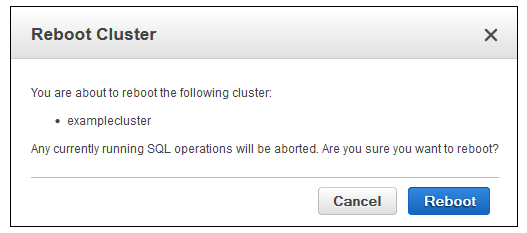
The main reason to restart a cluster by rebooting it is to apply changes to a parameter group. Note that it takes several minutes for a cluster to reboot, during which time you can’t access the cluster.
Further reading: Rebooting a Cluster
Resize
To resize a cluster:
- Select Clusters in the Redshift console, and select the cluster you want to resize.
- On the cluster details page, Select Cluster and Resize from the drop-down menu.
- Configure your resize parameters in the Resize Clusters window.
- Wait for the resize to finish.
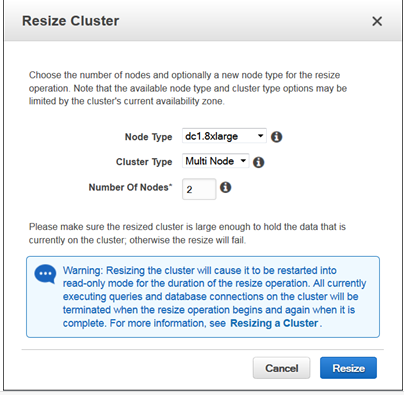
The ability to scale your data warehouse with no downtime is one of Redshift’s most important features. Resizing a cluster causes it to restart temporarily in read-only mode. All current queries and database connections stop during the resize operation, but are then resumed.
Further reading: Resizing a Cluster
Snapshot
Snapshots are point-in-time backups of a cluster. You can take a snapshot manually, or have Redshift create snapshots automatically. Snapshots can be copied to another AWS region for resilience purposes.
It’s possible to restore an entire cluster or a table from a historic snapshot. Below we show how to restore a table.
To restore a table from a snapshot using the Amazon Redshift console:
- Sign in to the Amazon Redshift console.
- Select Clusters and open the Table restore tab.
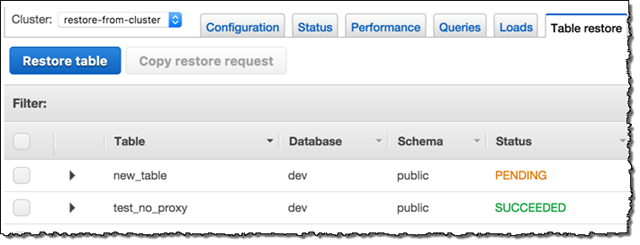
- In the Table restore panel, select a date range to find the snapshot. Select a snapshot and click Restore table.
- Fill in the details in the Table Restore dialog:
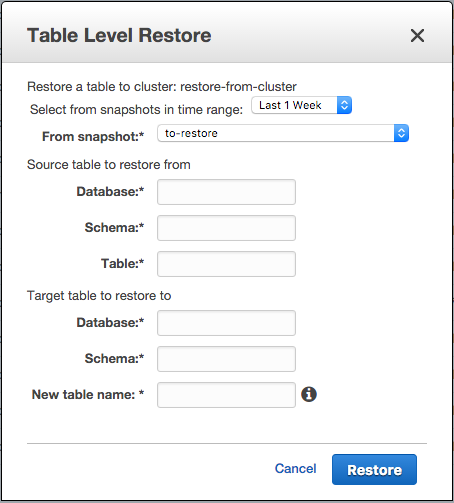
- Click Restore to restore the table.
For further reading, and to learn about additional cluster snapshot options, see Working with Snapshots.
Creating a Cluster in a VPC
An Amazon Virtual Private Cloud (VPC) is a cloud service that lets you launch Amazon Redshift and other AWS resources in a virtual network.
The two main benefits of an Amazon VPC are:
- The VPC offers superb security, with no access allowed to nodes from EC2 or any other VPC.
- Enhanced routing, which lets you tightly manage the flow of data between your Amazon Redshift cluster and all of your data sources.
Setting up Redshift Clusters in a VPC
Setting up a cluster in a VPC is similar to how you set one up in the console, with a few additional steps.
- You first need to set up a VPC. You can either choose the default VPC in your account or one that you create.
- Create an Amazon Redshift cluster subnet group specifying which VPC subnets can be used by the Amazon Redshift cluster.
- Give access to inbound connections for a VPC security group that will use the cluster.
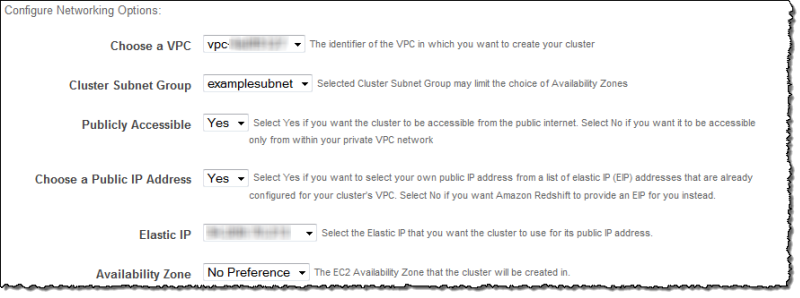
- Set up the cluster using the console as previously detailed. When you get to the Additional Configuration page, you can input the details of your VPC in the Configure Networking Options section.
Wrapping Up
Amazon Redshift is a fully managed cloud-based data warehouse in which you provision clusters of cloud-based computing resources (named nodes). You can manage a cluster using the Redshift console, the Java AWS SDK, Redshift’s CLI (with Python), or by using the Redshift Query API.
To create a cluster, you define a cluster parameter group, which are the settings used to configure the database. You then input the main cluster details such as cluster identifier, database name, and master user password, before choosing from one of two node types for your cluster.
Dense Compute nodes are optimized for high performance while Dense Storage nodes are optimized for storing high volumes of data. Clusters on Redshift are either single-node or multi-node.
Additional configuration options available during cluster setup include the option to encrypt the data within the cluster, and an option to configure networking settings. The main network setting to consider is whether to launch the cluster outside or inside a Virtual Private Cloud (VPC). A VPC lets you launch Amazon Redshift in a virtual network for added security and greater control over data pipelines.
Once a cluster is launched, you can modify, delete, reboot, or resize that cluster. The resize operation is an important Redshift feature that lets you scale your data warehouse with no downtime. You can also create cluster snapshots, which are point-in-time cluster backups that you can restore the cluster to in the event of a crash.
Amazon Redshift’s clustering mechanism uses Massively Parallel Processing (MPP) and columnar storage to analyze huge volumes of data at high speed. Redshift is ideal for enterprises that need a truly cloud-based representation of an on-premise data warehouse without the high entry costs, significant logistical concerns, and scalability challenges associated with on-site data warehouses (see our data warehouse architecture and data warehouse concepts traditional vs. cloud comparison).
Panoply is a cloud data platform that combines ETL and data warehousing with an easy-to-use interface you won’t find elsewhere. Panoply makes it easy to connect a variety of data sources, store it analysis-ready tables, and make it available to the analytical or BI tools you already use.
Learn more about Panoply.