Connect and analyze ALL of your data
Get insights from any data source, in a single source of truth
Get a Demo







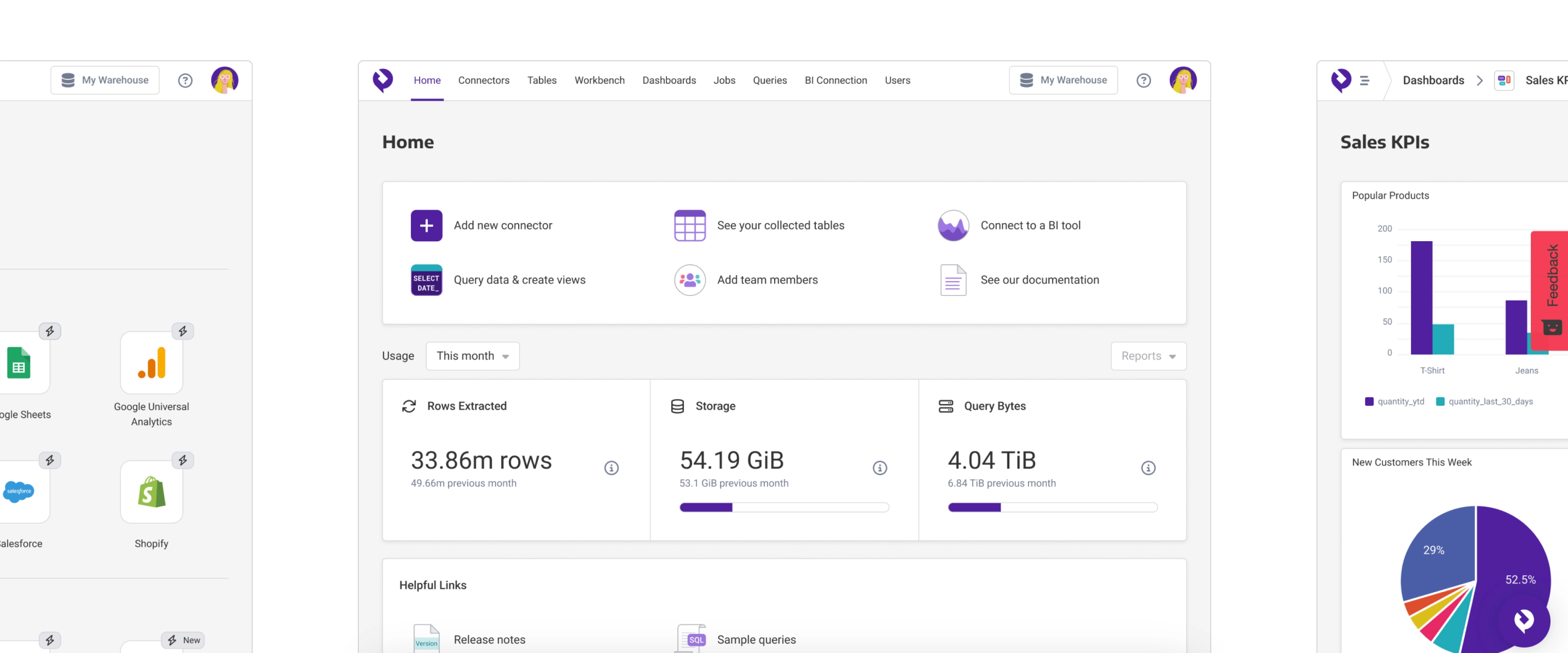
See Panoply Platform in Action

All-in-One
Sync, Store, and Leverage all your data to a Single Source of Truth platform
Unblock your data
Data driven startups and SMBs’ grows faster. Panoply’s low-code platform makes it easy for anyone in your organization to get fast insights from their business data.
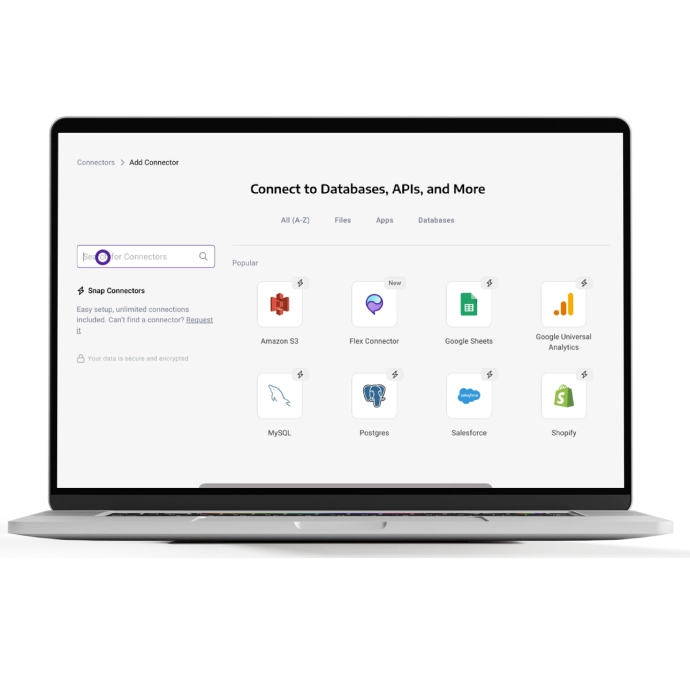
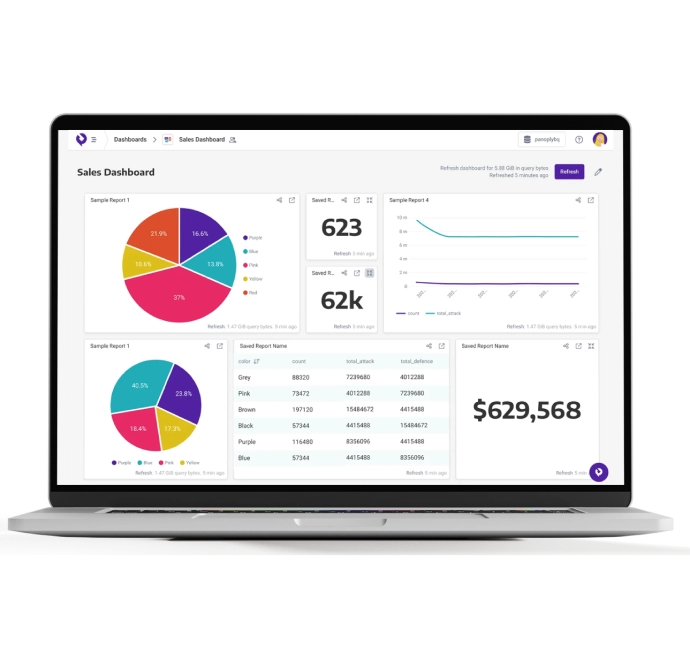
Upgrade your analytics
Panoply lets you sync, store, and leverage all your data in just a few clicks. Now you can upgrade your analytics quickly without engineering, and get even more insights.
Keep your data flowing without the fuss
Banish manual tasks with our all-in-one platform. Designed to eliminate chores like managing ETL pipelines and sifting through spreadsheets.


One platform. Democratized data for all.
Boost productivity across every team and role.
Better data for every industry

Better data for every industry








Grow faster with code-free platform
Connect, Explore, Visualize and Learn from your data about the next potential business opportunity.
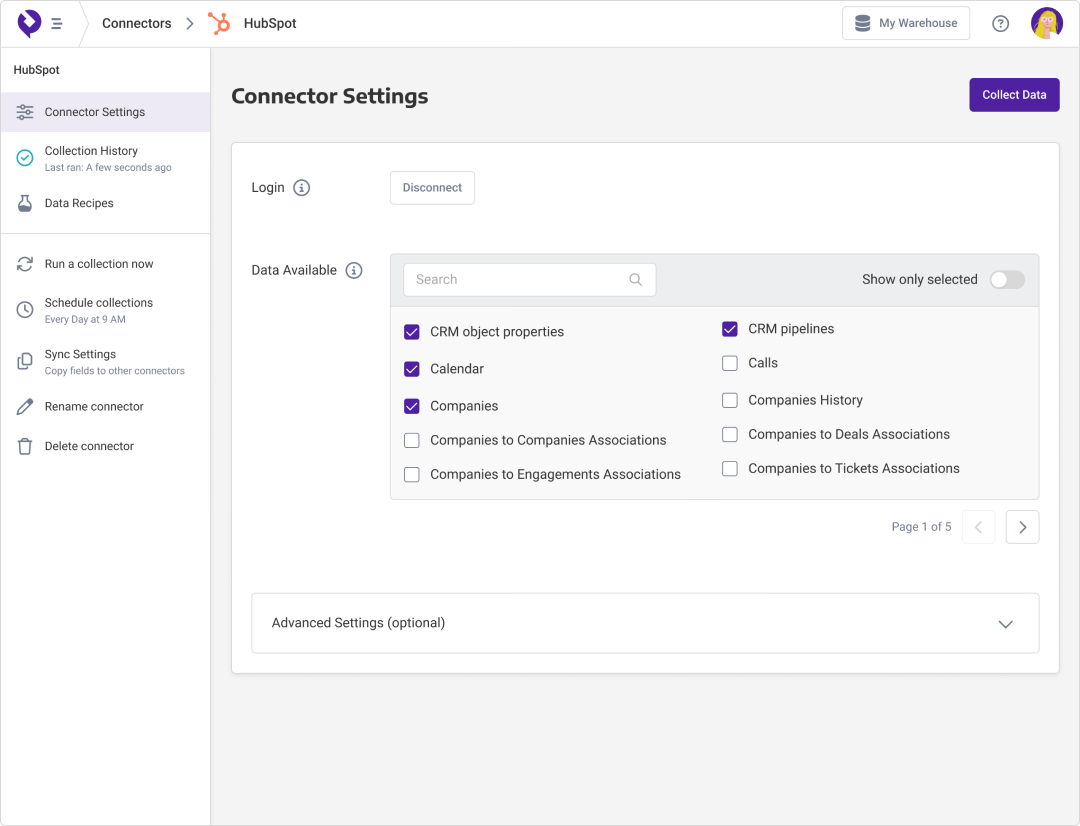
Managed ELT connectors with zero maintenance
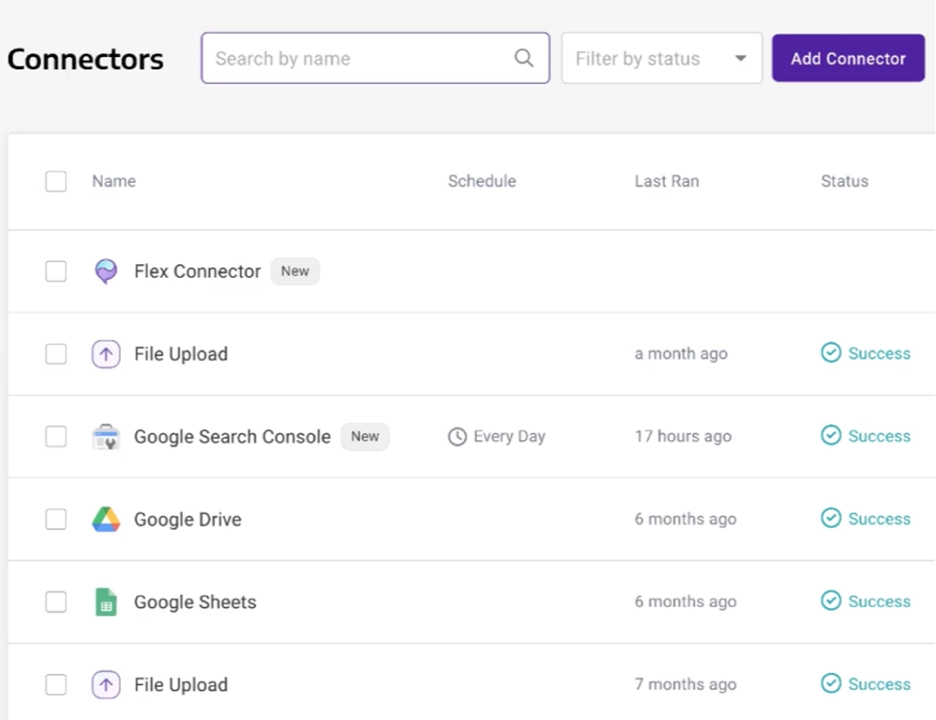
Code-free data connectors for popular API sources and the Panoply Flex Connector let you connect data from all your tools and platforms
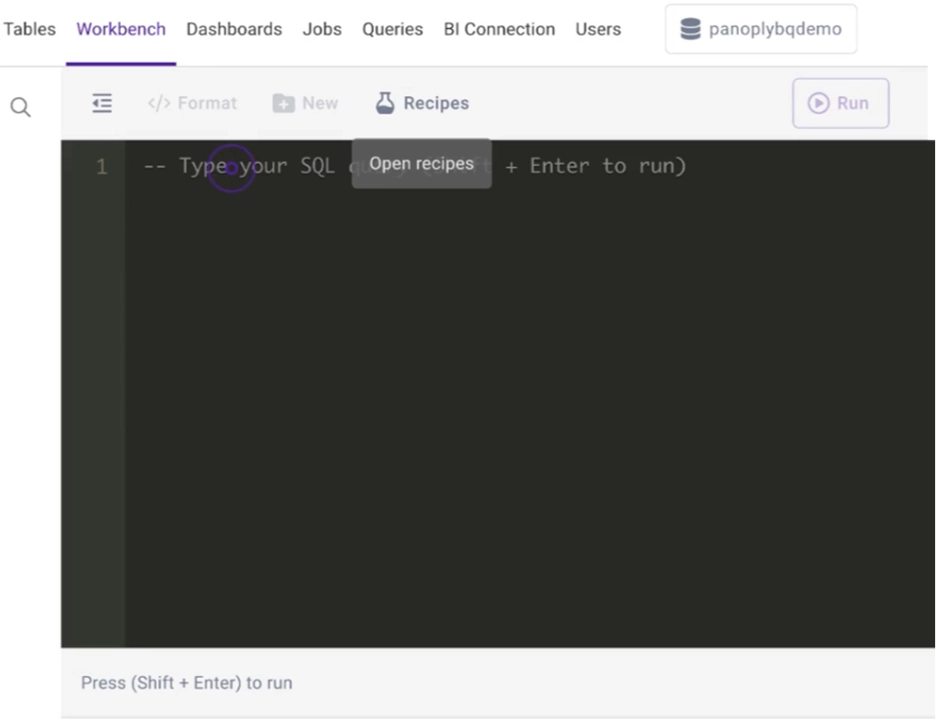
The Panoply workbench lets you explore your data in SQL

Fully-managed cloud data warehouse acts as a single source of truth for your data
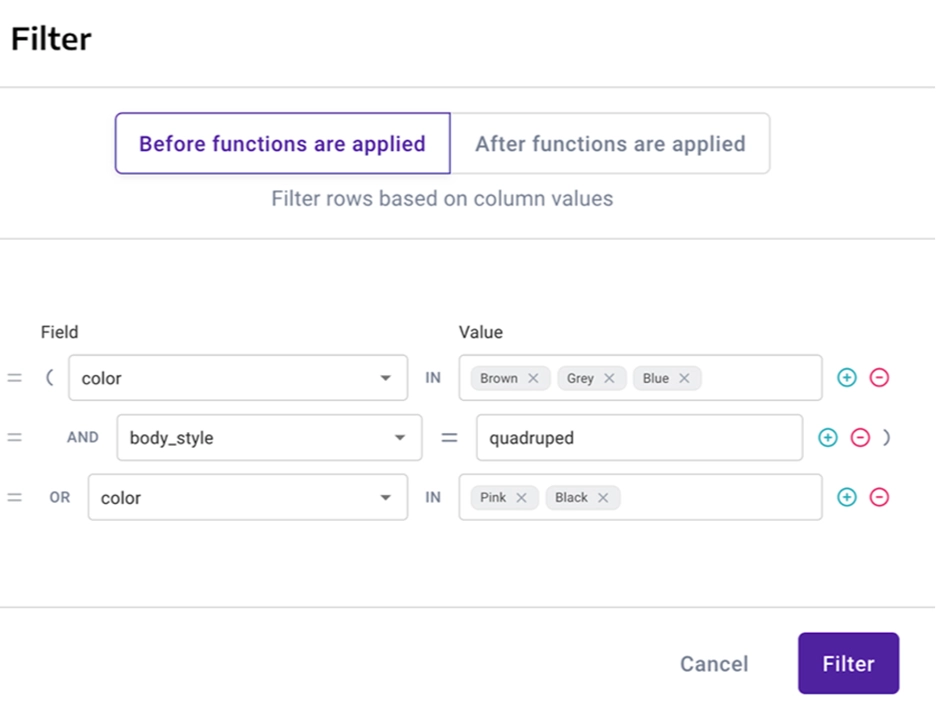
Drag-and-drop Query Builder for non-technical users to create queries in a few clicks
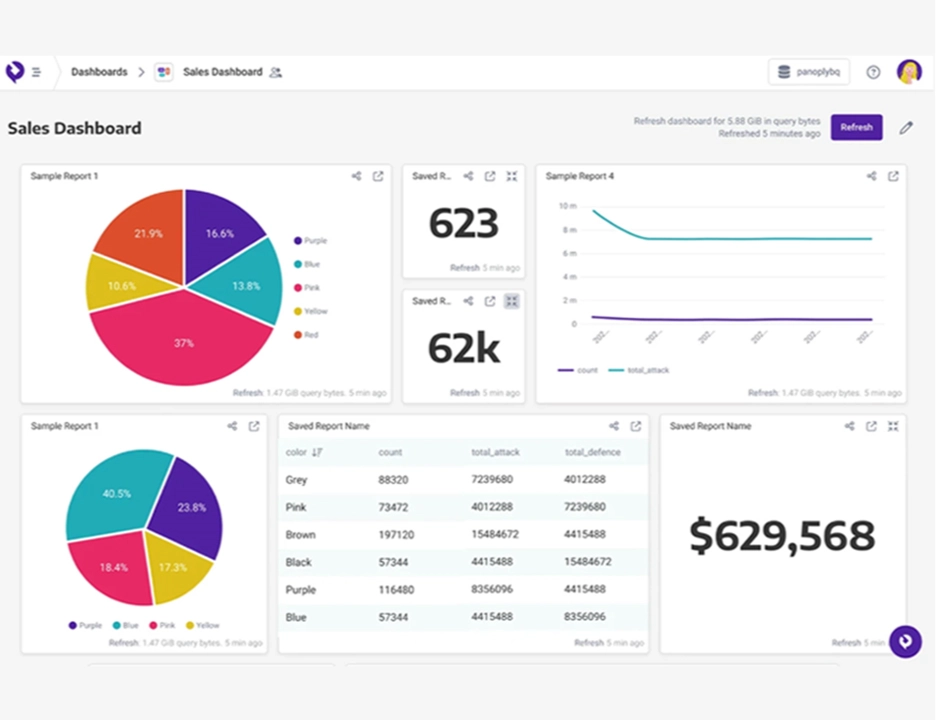
In-platform dashboards give you fast, actionable insights from all your business data
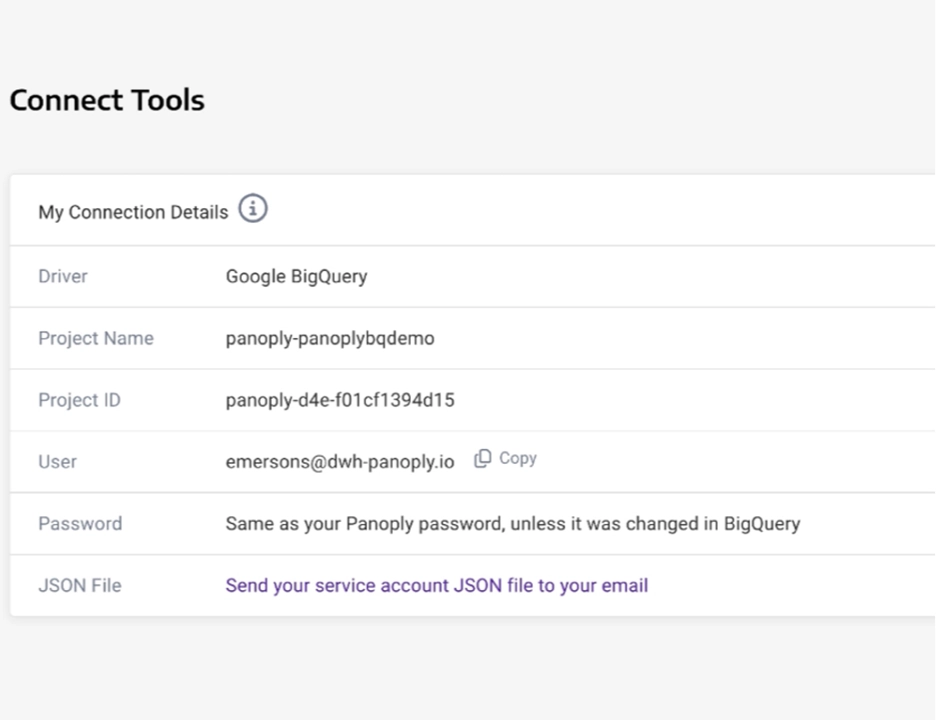
Easy connections to external BI tools
Award-winning customer support is with you every step of the way
Latest Thought Leadership
Browse through our recent top articles, whitepapers, and videos to get started on your path to better data.
Read all articles



Getting started is easy
Set up a data warehouse & connect your data in minutes.
SOC 2 - Type 2
Panoply has been audited against and found compliant with SOC 2 security, availability, and confidentiality principles by an independent auditor.
FINRA
Enable FINRA compliance by excluding sensitive data from your warehouse
GDPR
Stay GDPR compliant with different storage region availability
HIPAA
BAA available to maintain your PHI security and HIPAA compliance
FAQs
Panoply is a cloud-based, end-to-end managed data platform that allows you to start getting insights from your data in a matter of minutes. Our customers love being able to connect to almost any data source while also enjoying best-in-class support. Our customer success engineers are always here to support your data needs.
In addition to offering native, in-platform dashboards, Panoply was designed to enable users to connect their favorite business intelligence tools. The only prerequisite is that your BI tool of choice needs to be able to connect to BigQuery, as that's the backbone of the Panoply data warehouse.
Panoply is possibly the easiest data platform to setup and manage. Our solution has been designed to help users of all levels of technical expertise. From early stage startups to well established data teams, you’ll be amazed at how easy it is to have an end-to-end data infrastructure - from ELT pipelines, to storage, to dashboards - in minutes.
Yes! We offer a FREE 21-day Proof of Value that allows you to experience the full value of Panoply. You'll enjoy all the features and functionality of our platform. On day one, you'll be able to sync data from any data source and invite as many users as you'd like to access and analyze it. Click here to Start Your Free 21-Day Trial!
Panoply's pricing model is very flexible and we have packages to suit any organization's needs. Whether you're a startup or growing small-to-medium business, Panoply has the perfect package to suit your needs. You can view our pricing here: https://panoply.io/pricing/
Not to worry, we can help with that. One of the most praised features of Panoply is a built-in tool we call "Flex Connector". The flex connector allows you to connect to almost any API-based data source. Better yet, our team will set it up for you at no additional cost.
Panoply takes privacy and security very seriously, which is why we're SOC 2 and GDPR compliant and follow HIPAA guidelines. Please see our Privacy Policy for an overview of our security and compliance protocols.