Panoply Cloud Data Platform
Sync, store & leverage your data
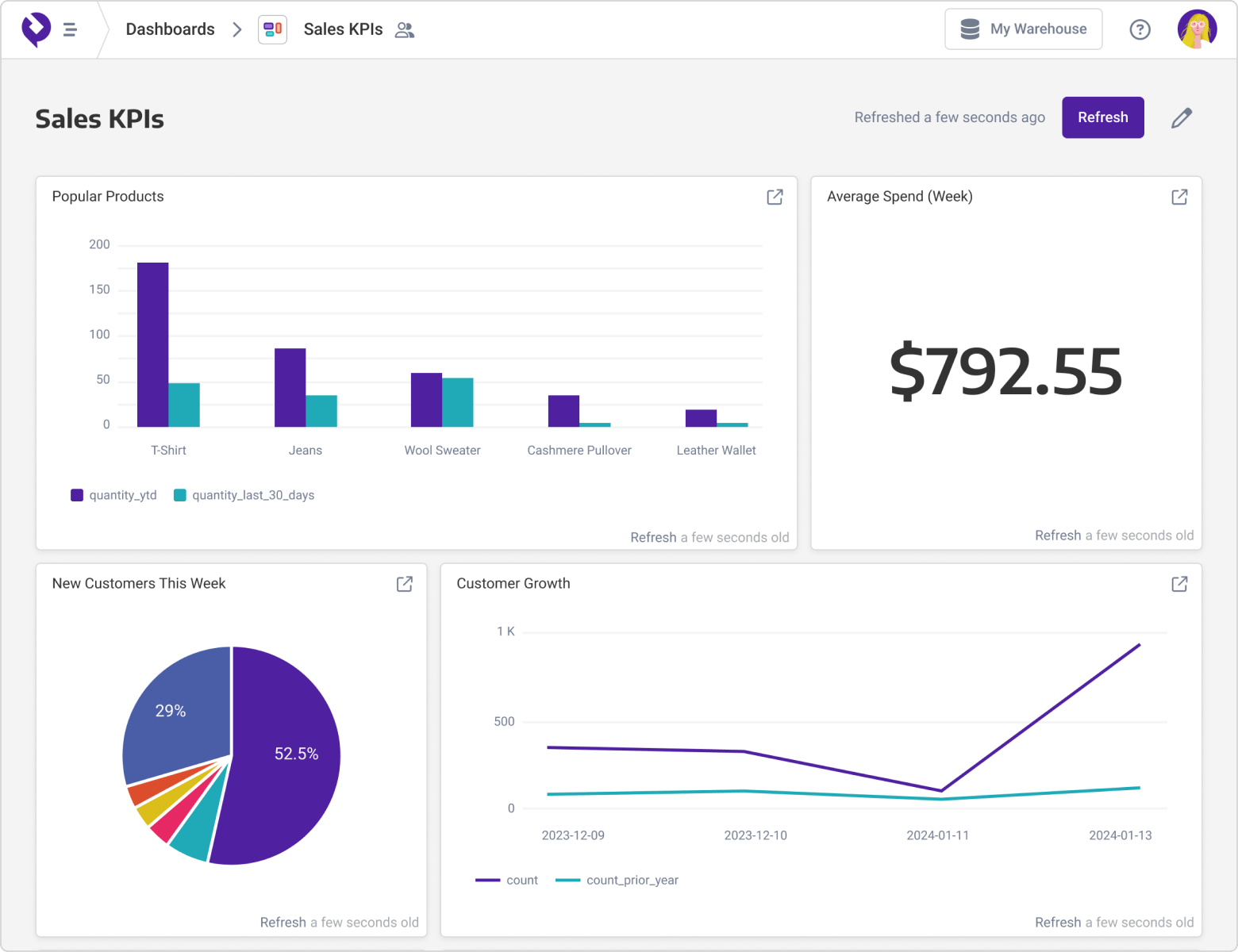


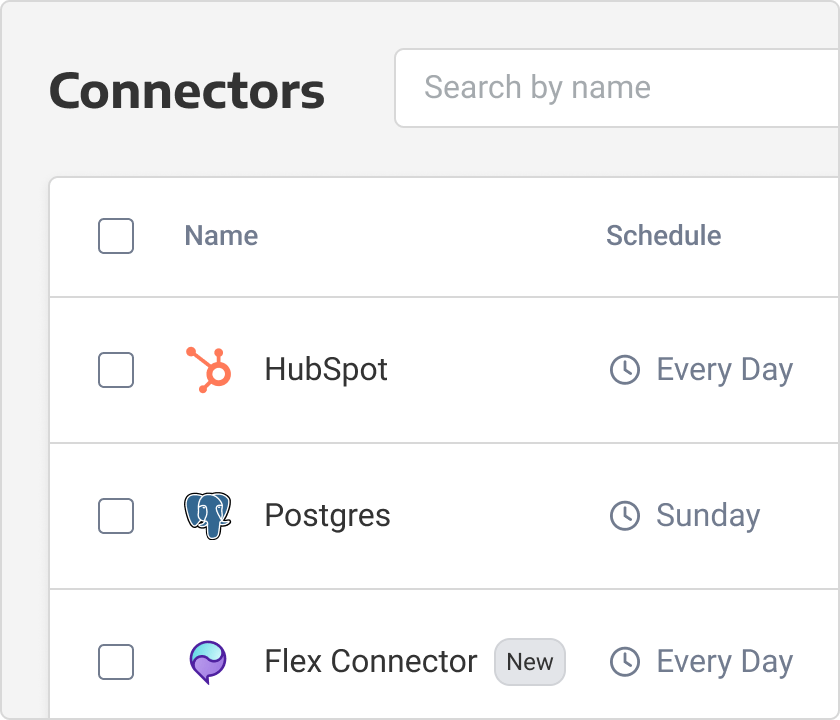
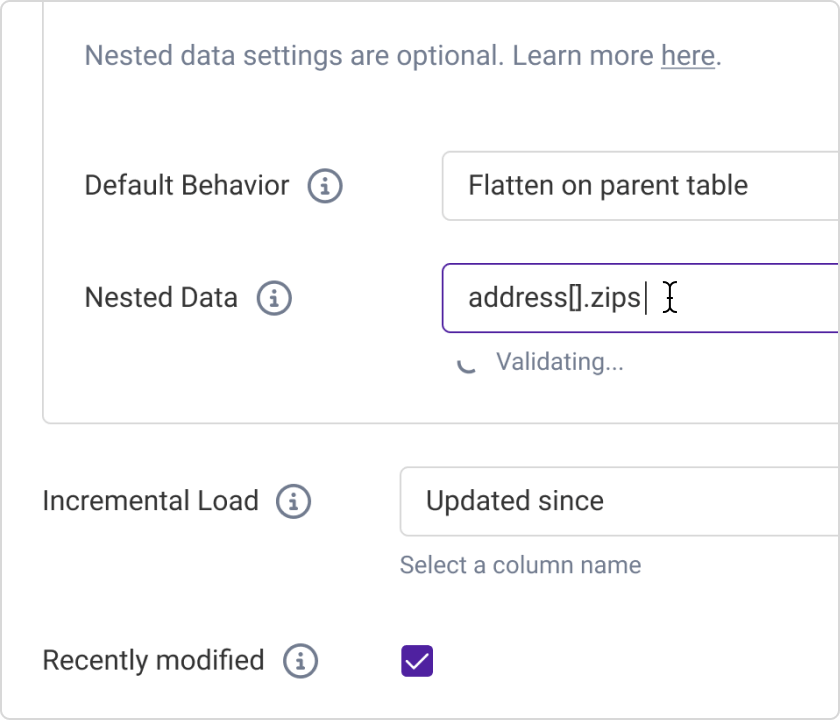

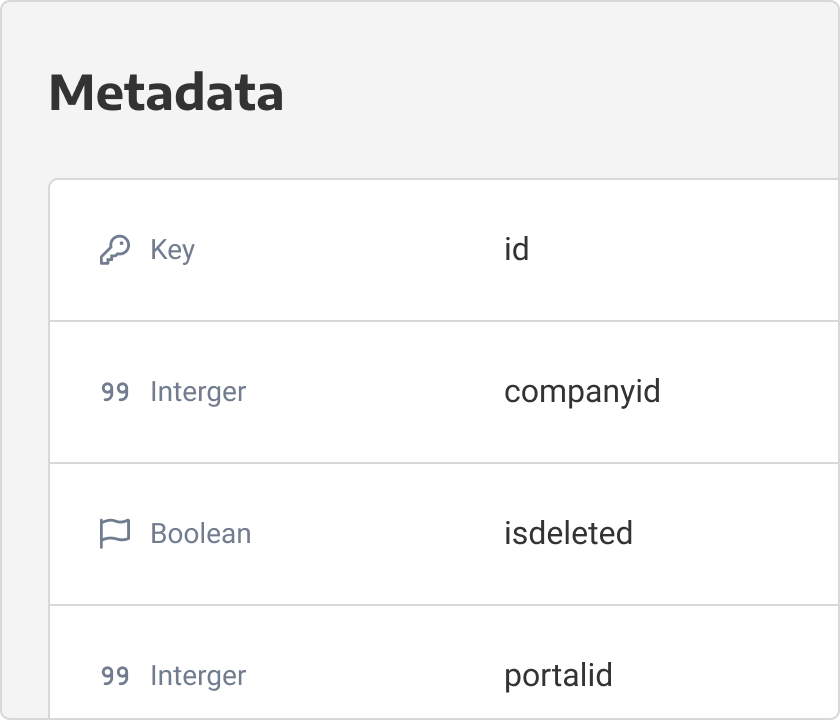
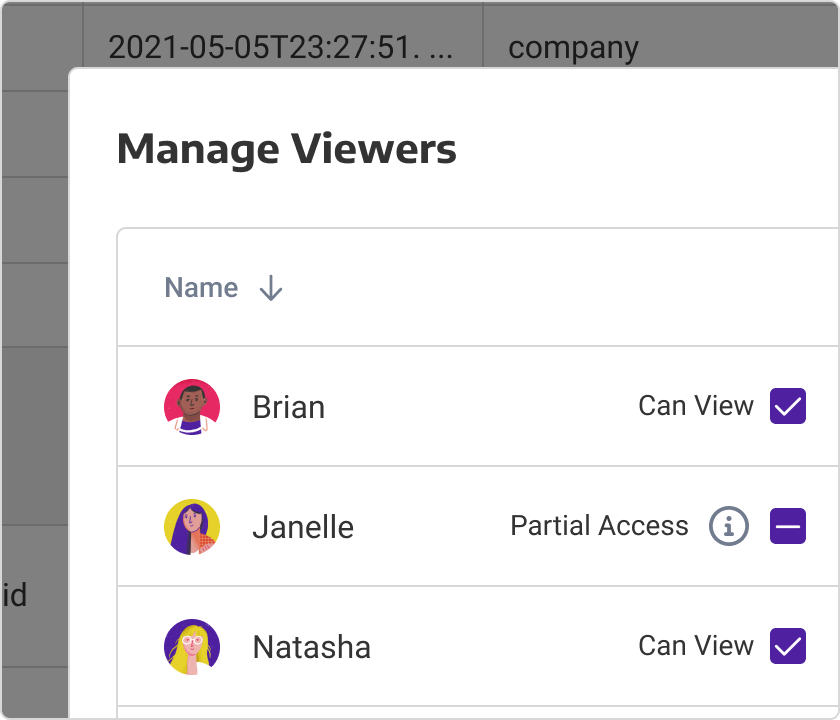






“ We were struggling to process a query on SQL Server/Crystal Reports which took 2.5 hours to run. With Panoply, we experienced almost a 70% improvement in runtime, down to 48 minutes!
Adam Bender - Director of Finance & BI, Park Dental