
ETL Tutorial: Get Started with ETL | Panoply Guide
The Extract Transform Load (ETL) process has a central role in data management at large enterprises. Whenever data makes the transition from production OLTP applications to OLAP and analytics applications, it needs to be extracted from the source system, transformed into a shape, form and structure suitable for the target system, and loaded into to the target system.
It’s difficult to provide a comprehensive ETL tutorial, because ETL is different in every organization. There is also a wide variety of tools that help organizations manage and automate ETL. In this guide, we’ll provide an overview of what ETL is, and a few generic examples of key ETL tasks, such as data extraction, header and trailer processing and data masking, which you can apply to your specific environment.
What is ETL?
Extract Transform Load (ETL) is a process which prepares raw data for consumption by enterprise systems, typically for reporting and analytics purposes. A common use case for ETL is in the data warehouse. ETL processes prepare OLTP data, for example day-to-day transaction data from finance, ERP or CRM, to be loaded into a data warehouse for reporting and exploration by BI tools.
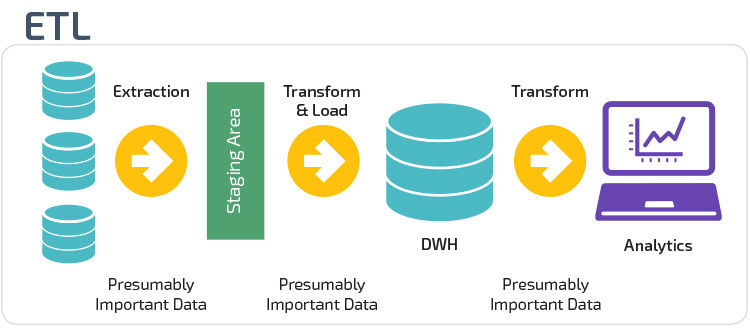
ETL tools have been around for two decades, and are extremely helpful in defining and automating complex ETL processes. Incumbent ETL tools include Informatica PowerCenter and IBM InfoSphere DataStage. There are newer cloud-based tools which can help set up ETL processes in a few clicks—these include Stitch and Blendo.
The ETL Process
The traditional ETL process is based on batch processing. ETL jobs run daily, weekly or monthly, and process large volumes of data from source systems. Here are the basics of the ETL process:
- Reference data — Create a set of reference data that defines permissible values your data may contain
- Data extraction — Extract data from sources, converting it from multiple formats like RDBMS, XML, JSON, CSV, etc. to a single standardized format
- Data validation — Validate data to ensure it contains the expected information in the correct format—otherwise subsequent ETL steps will not work
- Data transformation — Transform data by cleaning it, verifying its integrity, and aggregating or restructuring it to facilitate easy analysis
- Staging — Load data to a staging environment, to make it easier to roll back if something goes wrong
- Load to data warehouse — if everything looks good, push the data to your production data warehouse, either overwriting older data, or retaining it and managing historical versions with timestamps
ETL Examples—Common ETL Tasks
Following are a few generic examples of key ETL tasks. You can treat these examples as recipes, and implement them using your specific ETL tool or environment.
Data Extraction
Data extraction is the first step in the ETL process. Data extraction can take many different forms—data can be copied directly from storage devices, loaded via APIs, streamed via tools like Kafka, etc. Consider a simple example of data files uploaded to an FTP server, which need to be loaded to a target table in a data warehouse.
The recipe below uses a Type 4 Slowly Changing Dimension—data that is modified is stored in a separate history table with a timestamp for each historic version.
To extract source data transferred via FTP, while managing previous versions of the data:
- Maintain two tables—the target data table, and a history table, with previous, timestamped versions of each data field.
- Create an automatic trigger that detects a new file in a designated folder on the FTP server and pulls it to the ETL machine.
- Load data from the source file to a temporary table.
- Load the existing target table to a temporary lookup file.
- For each record in the source record, do the following:
- Validate the source data record and if it doesn’t pass validation, save it to a reject table (see the data quality recipe below).
- Check the record against the lookup table. If it does not exist, load to target table as a new record.
- If the record does exist in the lookup table, and the value has changed, save the new value to the history table, and then load the new value to the target table, overwriting the previous value. If value has not changed, do nothing.
Surrogate Key Generation
A surrogate key is a data field added by ETL engineers to manage data coming in from multiple sources. The surrogate key is a unique, numeric record identifier, which is mapped to original “natural keys” in the source data, such as customer IDs or transaction IDs.
To load data while generating a surrogate key—overwriting existing data:
- Select natural keys in the source data.
- Create a mapping table that maps all values of the natural keys to the new, numeric surrogate key. The table should include a value that denotes the maximum key number of the last data field loaded.
- Execute a loading process for each of the source files:
- Validate that the mapping table correctly maps all values of the source data.
- For each data record, check if the surrogate key already exists in the target table. If so, overwrite the same record.
- If surrogate key does not exist, add a new entry to the mapping table, add a new record to the target table, and increment the maximum key by 1.
A similar, slightly more complex process can be designed to load data while keeping a historical version of the data.
Header and Trailer Processing
Many data sources, including legacy sources and network traffic data, have records arranged in blocks with a header containing standard descriptive data, and a trailer at the end of each record.
To process header and payload:
- This type of processing is most easily performed using an ETL processing tool. Using a tool of your choice, extract the data, adding a separator within the file indicating header, body and trailer parts of the data.
- Using the separators, break the data into three tables: headers, body, and trailers.
- Refer to documentation of header and trailer format and convert into a usable form in the header and trailer tables.
- Make sure you retain a record ID that maps body data to headers and trailers.
Data Masking
It is a common requirement in data projects to mask, scramble or anonymize data. This might be necessary:
- When testing or staging data (to prevent sensitive customer data from being stored on non-production servers).
- When moving OLTP data to a data warehouse, the data might have to be anonymized to reduce privacy and security concerns, while still retaining the business-relevant information in each data record.
Strategies for masking or anonymizing data:
- Substitution — replacing each value in a sensitive data field with fake data from a dictionary table.
- Masking — adding characters like
*to replace sensitive data. For example, representing a 16-digit credit number with 12 asterisks, retaining only the last 4 digits. - Hashing — using a one-way function to turn the sensitive data value into a completely different value, but one which retains the same size and data format as the original.
- Shuffling — switching data randomly between data records.
- Randomization — randomly generating data to replace the original sensitive data.
Data Quality and Data Cleansing
Any ETL process is required to validate consistency and integrity of the data, and clean erroneous or non-standard data records. This is a crucial step which can undermine all subsequent processing steps, if not done correctly.
Consider a simple data quality process including two tests:
- Syntax test — identifying records that have an incorrect data pattern, invalid characters, incorrect data types, etc.
- Reference test — identifying records that have a correct data pattern but do not match up with known reference data—for example, an order including a product which does not exist in the products table.
To create an automated data cleansing process:
- For dates, check if date is in the correct format and satisfies business rules (for example, orders should be from the past week).
- For IDs, check if they contain correct characters and are in the acceptable range of numbers or characters.
- For addresses, check syntax and also check components of the address against a dictionary table of country, city and street names.
- For phone numbers, check format, allowing for international number formats, and check country codes against a dictionary table of acceptable countries.
- Similar checks for any other data field.
- Save all data fields with errors to a rejects file, to enable troubleshooting and manual data correction.
- For any data issue found, report a warning if the issue is not critical, and save the data to target table. Report an error if the issue is critical, and do not save the data to the target table.
Going Beyond ETL with ELT and Automated Data Management
Traditional ETL processes are the standard in many large organizations. But they are complex to build and test, and cumbersome to maintain. Many organizations are moving to new data warehouse infrastructure that supports Extract Load Transform (ELT).

In ETL, you simply load all data directly to the data warehouse, and then transform it later on-the-fly according to user requirements. This requires the ability to store large volumes of data and perform complex processing quickly, even when data is not pre-organized according to known queries. New data warehouse technology provides these capabilities.
An example of an automated data management system that supports ELT, doing away with the complexity of the ETL process, is Panoply. Panoply is a cloud data platform that allows you to load unlimited volumes of data, without complicated code.
Give Panoply a test drive and get a sneak peek at the future of ETL.