
Data Warehousing and Data Mining 101
In physical mining of minerals from the earth, miners use heavy machinery to break up rock formations, extract materials, and separate them from their surroundings.
In data mining, the heavy machinery is a data warehouse—it helps to pull in raw data from sources and store it in a cleaned, standardized form, to facilitate analysis. To continue the analogy, like mining engineers follow precise processes to extract precious stones from the surrounding dirt, data mining is a collection of techniques for sifting through raw data and discovering precious insights that can make a difference to the business.
Learn more about:
- Definitions of data warehouse and data mining
- Key differences between data warehousing and data mining activity
- Data mining principles used by practitioners to extract meaningful insights from vast data sets
- Common data mining analyses and their business applications
- Machine learning and NLP methods that power modern data mining projects
- The data mining process when data is stored in a data warehouse
- How to streamline data mining with next-generation data warehouse technology
What is a Data Warehouse?
A data warehouse is a relational database that stores historic operational data from across an organization, for reporting, analysis and exploration. Data warehouses are built to store very large volumes of data, and are optimized to support complex, multidimensional queries by business analysts and data scientists.
What is Data Mining?
Data mining involves deriving insights from large data sets. As its name metaphorically suggests, data mining is a process of carefully reviewing and processing large quantities of data (the “dirt”) to discover important patterns, findings or correlations (the “diamonds”) which might be important for the business.
In physical mining, it’s very difficult and time consuming to manually sift through dirt to find precious stones. Automatic tools make it easier to cover much more ground and go deeper into the earth in search of jewels. In data mining too, automation is essential to speed up the process, and go deeper in the breadth of data to derive insights.
Common uses of data mining include analysis and predictive modeling for marketing campaigns, pricing, fraud detection, financial forecasting, and analyzing website traffic.
Key Differences Between Data Warehousing and Data Mining
Stages in the Data Processing Pipeline
- The data warehousing stage involves collecting data, organizing it, transforming it into a standard structure, optimizing it for analysis and processing it.
- The data mining stage involves analyzing data to discover unknown patterns, relationships and insights.
Organizational Roles
- Data warehousing is part of the “plumbing” that facilitates data mining, and is taken care of primarily by data engineers and IT.
- Data mining is performed by business analysts or data scientists who have a deep understanding of the data.
Objectives
- Data warehousing is intended to provide the organization with a reliable source of data for many types of business analysis.
- Data mining is intended to provide the organization with hidden insights that cannot otherwise be gleaned from large-scale data.
Three Data Mining Principles
1. Information discovered must be previously unknown
It should be unlikely that the information discovered in data mining could have been hypothesised in advance. The data miner looks for something that is not intuitive—the further the information is from being obvious, the more valuable it is.
2. Information must be valid
Data miners should avoid spurious results that are not statistically or empirically valid. It is sometimes difficult to prove validity in data mining, but practitioners should aim to achieve the highest possible fit between model and analyzed data.
3. Information must be interesting or actionable
Some data mining tasks can produce thousands or millions of patterns, which are mostly redundant or irrelevant. Data miners should try to find the patterns or structures that are the most interesting for the business’s goals, based on statistical measures like frequency and subjective analysis.
Common Data Mining Analyses and Their Business Applications
Association Rules
- Definition: Objects that satisfy condition X are also likely to satisfy condition Y
- Business applications: Market basket analysis, cross selling/up selling, catalog design, store layout, financial forecasting, diagnosing likelihood of illness
Sequential Pattern
- Definition: Discovery of frequent subsequences in a collection of sequences, treating sequences with a different order separately
- Business applications: Marketing funnel analysis, natural disaster forecast, web traffic analysis, DNA analysis
Classification/Regression
- Definition: Discovery of a model or function that maps objects into classes or suitable values
- Business applications: Classification of customers for credit approval or selective marketing, performance prediction, diagnosing illness from known symptoms
Machine Learning and NLP Methods—The Intelligence Behind Data Mining
A key type of automation used in data mining projects is machine learning and natural language processing (NLP). These techniques make it possible to identify patterns and predict outcomes within large data sets.
Decision Trees
A series of IF/THEN rules that can be used for classification and prediction, typically in a supervised learning environment. A model is trained on a data set with known outcomes, and then attempts to apply the same decision structure to new, unknown data.
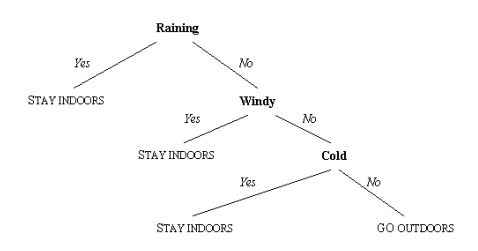
Decision tree algorithms include: CART, ID3, C4.5, C5.0, CHAID, Decision Stump, Conditional Decision Trees, M5
Supervised Machine Learning
Engines that train on a data set (input variable) with a known outcome (output variable), and iteratively make predictions until they arrive at a function that accurately maps the data set to the outcomes. The engines then apply the function to new data and can predict the outcome.
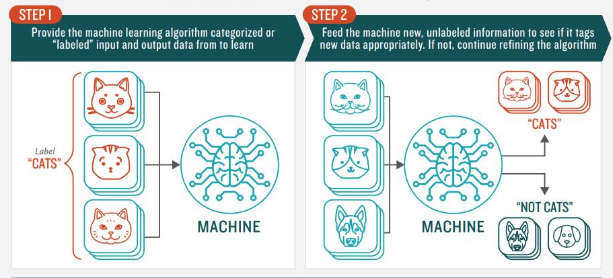
Supervised machine learning algorithms:
- Classification algorithms: Used when the output variable is a category such as “cats”, “dogs” and “mice”—Naive Bayes, AODE, BBN, Gaussian Naive Bayes, Multinomial Naive Bayes, Bayesian Network
- Regression algorithms: Used when the output variable is a quantitative value such as “$2.4” or “45%”—Linear Regression, OLSR, Stepwise Regression, MARS, LOESS, Logistic Regression
Unsupervised Machine Learning
Engines that work on input data without a corresponding outcome (output variable), and can be used to model the underlying structure of the data set. There is no correct answer—the algorithm is tuned to derive meaningful structure from the data.
Unsupervised machine learning algorithms:
- Clustering algorithms: Used to discover inherent groupings in the data, for example grouping movie lovers by the genre of movie they prefer—K-Means, LVQ, Self-Organizing Map, LWL
- Association algorithms: Used to discover a rule that accurately describes the data, for example products frequently purchased together—Cubist, OneR, ZeroR, RIPPER
Deep Learning / Neural Networks
Learning systems which simulate the human brain by creating large networks of digital “neurons” and using them to process pieces of a large data set. Learning systems can take in unstructured data sets, such as pixels of images, written documents or audio data, automatically recognize and extract features and classify them. Deep learning is used for a huge variety of tasks including face recognition, automatic translation and summarization, and pattern recognition.
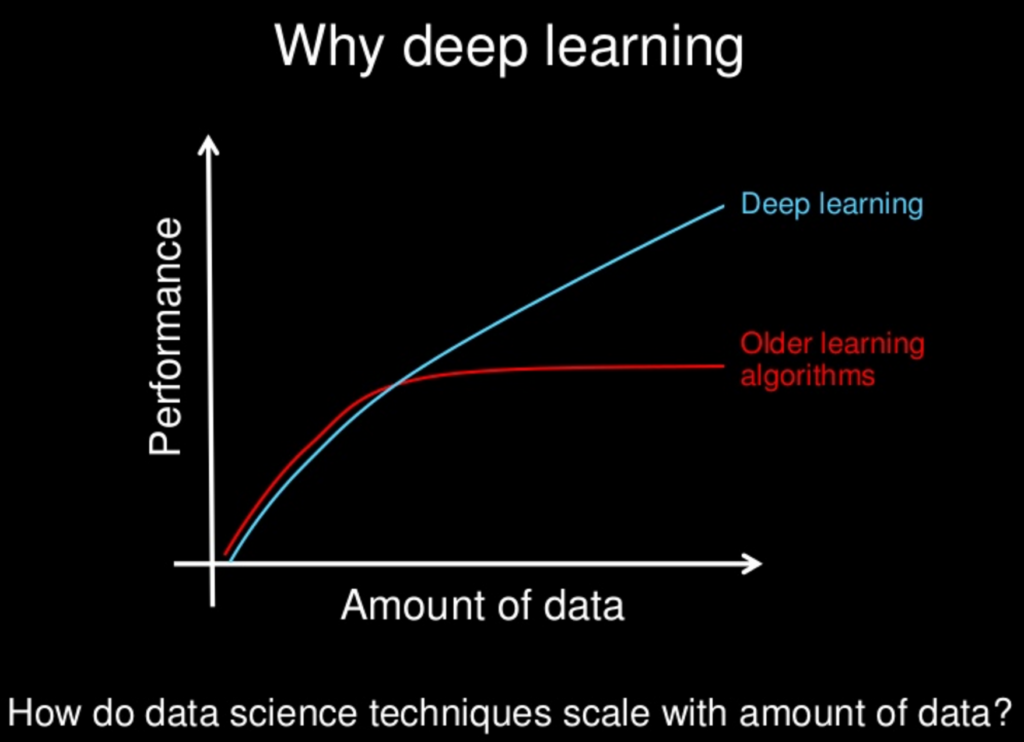
Deep learning algorithms: Multi-Layer Perceptron Networks, Convolutional Neural Networks, Long Short-Term Memory Recurrent Neural Networks
Natural Language Processing (NLP)
NLP is a general term for the automated processing of human language. Modern NLP technology uses primarily machine learning techniques to process human language, parse it, break it down into sentences and words, and understand semantics.
In the context of data mining, some common applications of NLP are:
- Entity extraction: Detecting names and concepts in large volumes of text
- Sentiment analysis: Understanding the emotion embedded in language, for example positive vs. negative reviews
- Relationship extraction: Understanding relations between elements in a data set
- Topic recognition / tagging: Automatically classifying material into topics or categories
- Disambiguation: Understanding what is the contextually-appropriate meaning for a word that has multiple meanings
- Summarization: Automatically generating a reliable summary of a chunk of text
Data Mining Process When Using a Data Warehouse
Data mining projects do not require a data warehouse infrastructure. But large organizations usually perform data mining on top of data stored in the data warehouse, according to the following general process:
- Data ingestion: Data engineers load relevant data into the data warehouse
- Data selection: Data engineers select relevant data sets and removes irrelevant data
- Data preparation: Data engineers pre-process and clean the data to improve quality and remove “noise”
- Data transformation: Data engineers transform the data into a format suitable for machine learning analysis
- Data mining: Data engineers run the data through one or more machine learning or NLP models to extract relevant insights
- Analysis of results: Data miners examine results and fine-tune models to determine validity and business relevance
- Assimilation of knowledge: Data miners prepare reports explaining the insights derived and their business value
Effortless Data Mining with a Next-Gen Data Warehouse
Data mining is an extremely valuable activity for data-driven businesses, but also very difficult to prepare for. Data has to go through a long pipeline before it is ready to be mined, and in most cases, analysts or data scientists cannot perform the process themselves. They have to request data from IT or data engineers and “wait in line” until the data is cleaned and prepared.
This was true for traditional data warehouses. However, next-generation data warehouse technology takes care of much more than just storing the data and facilitating queries. For example, Panoply combines ETL and data warehousing with a user-friendly interface designed to make it easy to go from raw data to real insight. Data miners can use a point-and-click interface to select data sources, ingest vast amounts of raw data, and bring it to a state which enables data mining analysis, without any complicated code.
Get a free trial of Panoply and try a data warehouse built to assist analysts and data miners in their journey to new insights.